


What are the latest trends in AI
“What are the 5 emerging trends in AI?” or “What are AI trends in 2023?” You will often see these questions are shared among professionals and businesses seeking to integrate AI advancements into their work.
Indeed, keeping pace with the swift, diverse developments in AI is often a challenge even for experts. Yet, every autumn, there’s an easy answer to this question: the ‘State of AI’ report. This annual publication highlights and explains the progress and shifting paradigms within the AI realm into an accessible, comprehensive summary.
As we delve into the 2023 edition, we prepare to unpack insights that both continue established trajectories and disrupt long-held assumptions. As we embark on this summary, we invite those who are curious about AI to not just understand AI’s current state but to anticipate its future directions. In the remainder of this article, we have highlighted a few of the most compelling findings that are worth considering for those that want to have a quick overview of what AI is all about in 2023. In the first version of our summary, we are highlighting all relevant conclusions about large language models (LLMs). While we offer but a glimpse into the field, we can recommend reading the full report to gain even more insights.
GPT-4 is (still) the king
When wondering which AI model is still the best LLM the answer is clear: GPT-4. Most people will have had access to GPT-4 via ChatGPT and it is truly impressive what the LLM can provide. Furthermore, it is more than ‘just’ a text model. Recent updates have made it multimodal, meaning, it can interact with audio and images as well. These updates have made it possible to create images, to speak to GPT-4 and to have it analyze uploaded images as well. While it still hallucinates, meaning that it can very confidentially provide wrong answers, it is 40% more often correct than its predecessor models. When it comes to bank for your buck, GPT-4 still leads the field when it comes to model capacities.

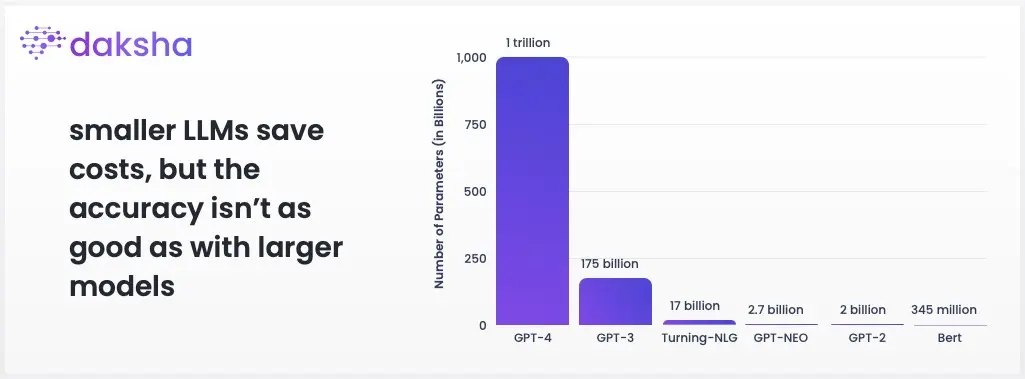
Size Matters in LLMs
Some researchers and companies have advocated the use of smaller LLMs to save training and ‘answering’ costs. Researchers have found that while using smaller LLMs can indeed save costs and provide answers with a good language style, the accuracy isn’t as good as with larger models. Especially when smaller models try to imitate their larger cousins, they often go wrong in their judgement. But not all hope is lost for those that cannot afford several million dollars on the training of AIs. A technique called RLHF provides hope as unmatched writing capabilities of LLMs can be reached, even surpassing humans in some tasks.
LLaMa-2: A new publicly available power model trained with RLHF?
July 2023 saw the unveiling of the LLaMa-2 series, an advanced model series with a unique proposition: the freedom for commercial use by nearly everyone. While the foundation of LLaMa-2 mirrors its predecessor, LLaMa-1, it boasts the previously discussed RLHF, specifically tailored for dialogue interactions. It became rapidly apparent that the model, while being smaller, fills the gap when using expensive GPT-4 calls can be considered overkill. By September 2023, the model’s popularity was evident, clocking in at an impressive 32M downloads.
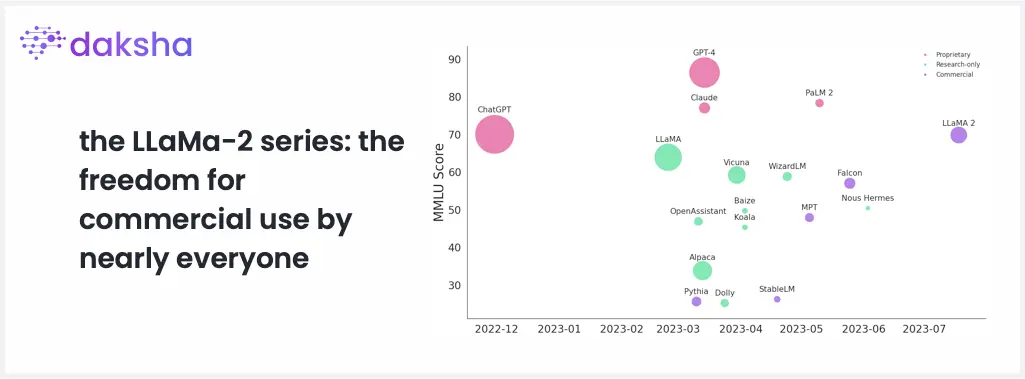
The graph above shows the release date of a model as well as its performance on the MMLU (the Massive Multitask Language Understanding) task. From the official State of AI 2023 report
Context Length: The New Gold Standard in AI Performance?
Historically, the parameter count has been the go-to metric for estimating the potential of AI models. Often, models are described with regard to how many billion parameters they have, suggesting that this indicates their performance. However, the true test of a model’s ability might lie in its capacity to process and handle lengthy inputs. GPT4 has an impressive context length of over 8,000 tokens even reaching 16,000. This equates to around 6,000 and 12,000 words, respectively. Longer context length equals more use cases as more information can be passed to the model in the form of long prompts or long text documents. As such, context length has emerged as a pivotal focus in AI research.
However, All That's Long Doesn't Shine
While many companies aim to increase the context lengths of their AI models, recent studies have highlighted a surprising trend: models often perform optimally when crucial information is placed at the beginning or end of an input. A noticeable decline in performance is observed when essential data is nestled in the middle. Furthermore, as input length swells, the efficiency of models appears to be degrading. This raises questions about the ideal balance between context length and effective AI comprehension, suggesting that the hunt for the ever-increasing context length may be a fool’s errant under the current AI systems.
The Evolution of Prompting: A Dive into Advanced Techniques
The art of prompting has taken a sophisticated turn. The efficacy of a task is no longer only dependent on the input but on the quality of the prompt itself. In the past months, new techniques have been developed that improve the performance of any LLM they are used with. For example, Chain of Thought (CoT) prompting, where LLMs are instructed to detail their ‘thought’ processes, leads to enhanced performance. The Tree of Thought (ToT) takes this a step further, using multiple sampling and organizing the “thoughts” into tree-structured nodes, in use similar to a voting mechanism, offering deeper insights. These findings suggest that it is not only important to which LLM you are using, but also how you are instructing the model.

The Unpredictable Nature of Continuous Model Updates
While the underlying LLM performance remains a cornerstone for downstream tasks, the AI community faces a challenge with OpenAI’s undisclosed modifications to their GPT models. Despite being under the same version label, users have reported significant performance variations over time. This has led to the need for constant vigilance, requiring continuous performance checks and prompt readjustments. As we have discussed in our previous article, this highlights the need for reliable means of testing LLM applications.
Takeaways from the State of AI report 2023 – Part 1
For newcomers to AI and business users, several insights from the current state of AI are particularly worth noticing. Firstly, while the prowess of large models like GPT-4 is undeniable, the emergence of alternatives like LLaMa-2 highlights a growing diversification in the tools available. Organizations, especially those with limited resources, no longer have to rely solely on resource-intensive models but can leverage efficient, cost-effective solutions without compromising on output quality.

The findings about context length and model prompting underscore the understanding required for effective AI application. It’s not about utilizing the most extensive model or input but about strategically harnessing model capabilities, be it through optimal information placement or sophisticated prompting techniques.
Lastly, the AI field’s dynamic nature, characterized by unannounced updates, requires users to maintain a hands-on approach to their AI tools. Regular performance assessments and adaptability to prompt restructuring are becoming integral for maintaining consistent output quality.
Businesses and individual users must navigate these insights with a blend of strategic integration, continuous learning, and adaptability to harness the full potential of evolving AI technologies effectively. The speed with which AI is developing seems to be only increasing, encouraging us to stay up to date. To continue with this effort, next week, we will touch upon AI hardware, non-LLM trends and legal developments with regard to using AI.

By Marvin C. Kunz -Marvin’s primary role at Daksha is to merge the wisdom of psychology with the potential of AI and Prompt Engineering. When he is not busy with that, you can find him talking to strangers about virually anything under the sun!